One of my passions is street photography, but I have a backlog of photos dating back more than three years that I still want to process. Street photography is about capturing moments that tell stories but when you’re shooting hundreds or even thousands of photos in a year, they quickly add up. Having captions for images not only helps with retrieval but also with remembering the interesting ones. Writing detailed captions for a large collection of photos, however, becomes a massive bottleneck. Last year, I built a blur and common lighting problem detector that flags images, and it helps me tremendously. Still, the traditional workflow means spending hours writing captions for every photo worth keeping. This is where vision models become incredibly useful not as a replacement for your artistic eye, but as a powerful first-pass tool that can identify and describe things you might have missed or forgotten about.
Models and Prompting#
Alibaba’s Qwen team has released Qwen2.5-VL, Google has Gemma 3, Meta has Llama 3.2-Vision/Llama 4, and Mistral Small 3.2 offers powerful capabilities offline. Vision models can analyze your street photography with surprising depth and accuracy. Writing captions for street photography isn’t just about describing what’s obviously in the frame. Good captions help me understand the context, notice subtle details, and go beyond what’s immediately visible. I’m experimenting with using LLMs to write the human stories happening in the image they can turn a snapshot into a narrative. And considering how good text-to-audio has become, I can even make my own audiobooks centered around those photos.
Vision models don’t just identify obvious subjects like “person walking” or “building in background.” They can pick up on clothing styles and fashion choices, facial expressions and body language, architectural details and urban design elements, signage and text that add context, lighting conditions and mood, interactions between people, cultural and social cues, and even technical aspects of your photography such as depth of field and composition choices. Obviously, this all goes into a prompt. By using different prompts and multiple runs that process each image, I can identify street art, describe the general age and style of architecture, note weather conditions, and even pick up on the overall mood or energy of a scene based on how people are positioned and interacting.
Practical Prompt Examples for Street Photography#
When working with vision models for street photography analysis, the quality of your prompts directly affects the usefulness of the generated captions. Instead of just asking “describe this image,” try something like “Provide a detailed description of this street photography image, including the main subjects, their apparent activities and interactions, architectural and environmental details, mood and atmosphere, any text or signage visible, and interesting visual elements that contribute to the story.” This gives you comprehensive raw material to work with when crafting your final captions. Also the context size and the size of image is important, so reduce the quality and size of the image before giving to the LLm to conserve tokens.
Here are some effective prompt templates and some examples that I tested on:
Basic Street Photography Analysis:
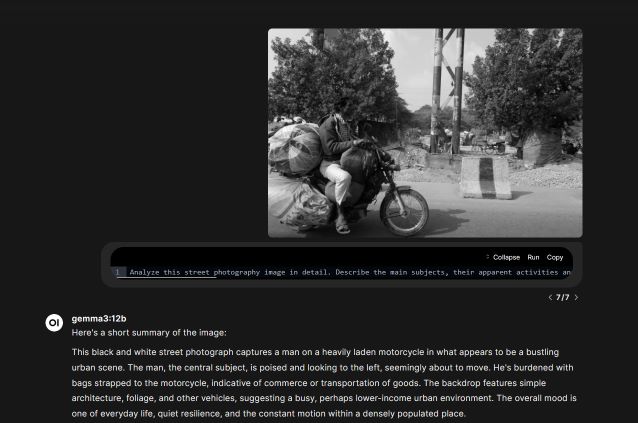
Analyze this street photography image in detail. Describe the main subjects, their apparent activities and interactions, the architectural and environmental context, the mood and atmosphere, any visible text or signage, and interesting visual elements that contribute to the urban narrative. Focus on human elements and city life details that tell a story about this moment and place.
Technical and Artistic Analysis:
Provide a comprehensive analysis of this street photograph including: 1) Composition and framing techniques used, 2) Lighting conditions and how they affect the mood, 3) Depth of field and focus choices, 4) Human subjects and their apparent activities, 5) Urban environment and architectural details, 6) Cultural and social context visible in the scene, 7) Any text, signage, or graphic elements that add meaning.
Contextual and Cultural Focus:
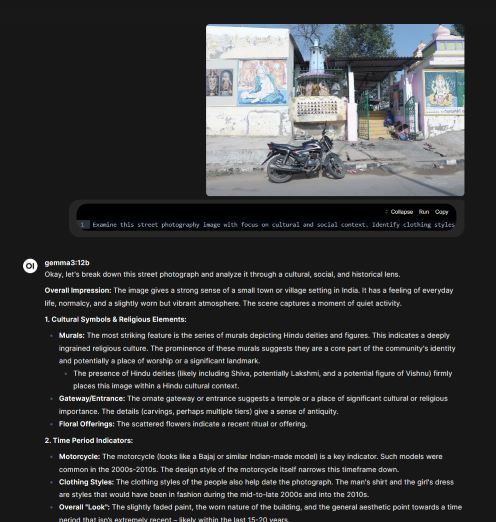
Examine this street photography image with focus on cultural and social context. Identify clothing styles and fashion choices, apparent time period indicators, architectural style and urban design elements, social interactions and body language, economic and demographic indicators, and any cultural symbols or text visible. Help me understand what this image reveals about the place and time it was captured.
Story and Narrative Extraction:
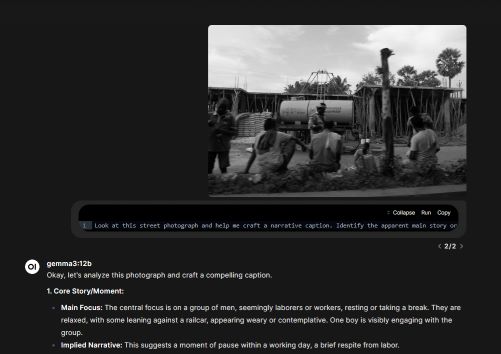
Look at this street photograph and help me craft a narrative caption. Identify the apparent main story or moment being captured, secondary characters and background activities, environmental details that set the scene, emotional undertones and mood indicators, and temporal clues about when this might have been taken. Suggest what might have happened just before or after this moment.
Summarizing as part of the system context is a good idea to have for the first pass since LLMs can give very large descriptions from these smaller prompts:
Building This Into Your Long Term Photography Practice#
Once you establish a workflow using vision models for caption writing, you’ll probably find that it changes how you think about your photography more broadly especially when it comes to maintaining your authentic voice and personal style. Having detailed descriptions of your images makes it easier to search and organize your photo library, identify recurring themes in your work, and understand your development as a photographer over time. The comprehensive analysis also helps with keyword tagging and metadata management, which becomes increasingly important as your photo archive grows. The goal isn’t to copy and paste AI-generated descriptions directly as your captions, but to use them as detailed reference material for writing authentic, personal captions that reflect your vision and voice as a photographer.
Read through the AI-generated descriptions and identify the elements yourself. Use those details as building blocks for captions that sound like you and capture what you actually wanted to communicate about the scene. The best approach is to treat AI descriptions as extremely thorough research notes tools that help you remember and notice details you might otherwise overlook and then write captions that combine those observations with your unique perspective and storytelling ability.
It’s also interesting to consider how easy it has become to replicate what services like Google Photos do for automatic image analysis. While Google Photos relies on proprietary models and vast computational resources, the core concepts of image embedding and semantic search are now accessible through open-source tools and models. You can set up a similar system using local vision models or CLIP-based approaches, giving you complete control over your data and processing pipeline.