
I have been a fan of local models for a long time, even when I cannot host the largest ones myself. Privacy and cost matter, but reproducibility matters more to me. A downloadable model can be frozen in time. I can preserve the weights, inference settings, prompts, and supporting code, then query the same model years later. Hosted APIs rarely provide that guarantee. A provider can update the model, change its system prompt, adjust its routing, or retire the version I was using. When a local workflow changes, I can check my own code first instead of wondering whether the model changed underneath it.
For the last three months, my inference setup has followed one rule: run the agent locally first.Local agents cover most of my coding, search, file editing, and small automation work. They keep project context on my machine and give me a fast feedback loop without sending every prompt to a hosted service. When the local model reaches a concrete limit, I move the same task to OpenRouter. I am not looking for the model with the highest score on every benchmark. I want a model that completes the task at a cost that makes repeated agent runs practical. The hosted model market has also concentrated around a small number of companies. For many developers, the default choice is Claude or ChatGPT, with Gemini as another large but distant platform. Models from DeepSeek, Qwen, and Moonshot provide another route to capable text and coding inference.
My setup has three layers:
- Local models for routine work.
- OpenRouter for larger context windows, stronger reasoning, or coding tasks that need more compute.
- Direct provider APIs when caching, quantization, or provider pricing changes the result.
Models and prices shown in OpenRouter#
The figures below come from the OpenRouter pages in the screenshots I captured. Prices are per 1 million tokens.
| Model | Input | Output | Context | Release date | Provider details shown |
|---|---|---|---|---|---|
| Qwen3.7 Max | $1.25 | $3.75 | 1M | May 21, 2026 | Alibaba Cloud International; 1.24s latency; 47 tokens/s; 100% uptime |
| DeepSeek V4 Pro | $0.435 | $0.87 | 1M | April 24, 2026 | DeepSeek; 1.33s latency; 50 tokens/s; 99.99% uptime |
| Kimi K2.7 Code | $0.75 | $3.50 | 262K | June 12, 2026 | Ambient; 1.00s latency; 51 tokens/s |
| DeepSeek V4 Flash | $0.09 | $0.18 | 1M | April 24, 2026 | Cloudflare and DigitalOcean listed among the providers |
| Qwen3.7 Plus | $0.32 | $1.28 | 1M | June 3, 2026 | Alibaba Cloud International; 0.82s latency; 32 tokens/s; 100% uptime |
A coding agent can consume millions of tokens while reading a repository, planning changes, checking files, running tests, and retrying failed edits. The prices in the table change how long I am willing to let an agent continue before I stop it or move the task elsewhere. My experience is narrower than a benchmark result. For many of my text and programming tasks, these models deliver about 95 percent of the result I need at less than 5 percent of the cost of the highest-priced APIs. That estimate comes from my own prompts, repositories, and tolerance for correction turns. It is not a general measurement of model quality. The remaining gap still matters. A cheaper model can lose track of a refactor, repeat a failed approach, or require more planning from me. I switch models when the correction loop costs more time than a stronger model would cost in tokens.
Qwen3.7 Plus and Qwen3.7 Max#
Qwen3.7 Plus is one of my starting points for general work. It accepts text and image input, returns text, and has a 1 million token context window.
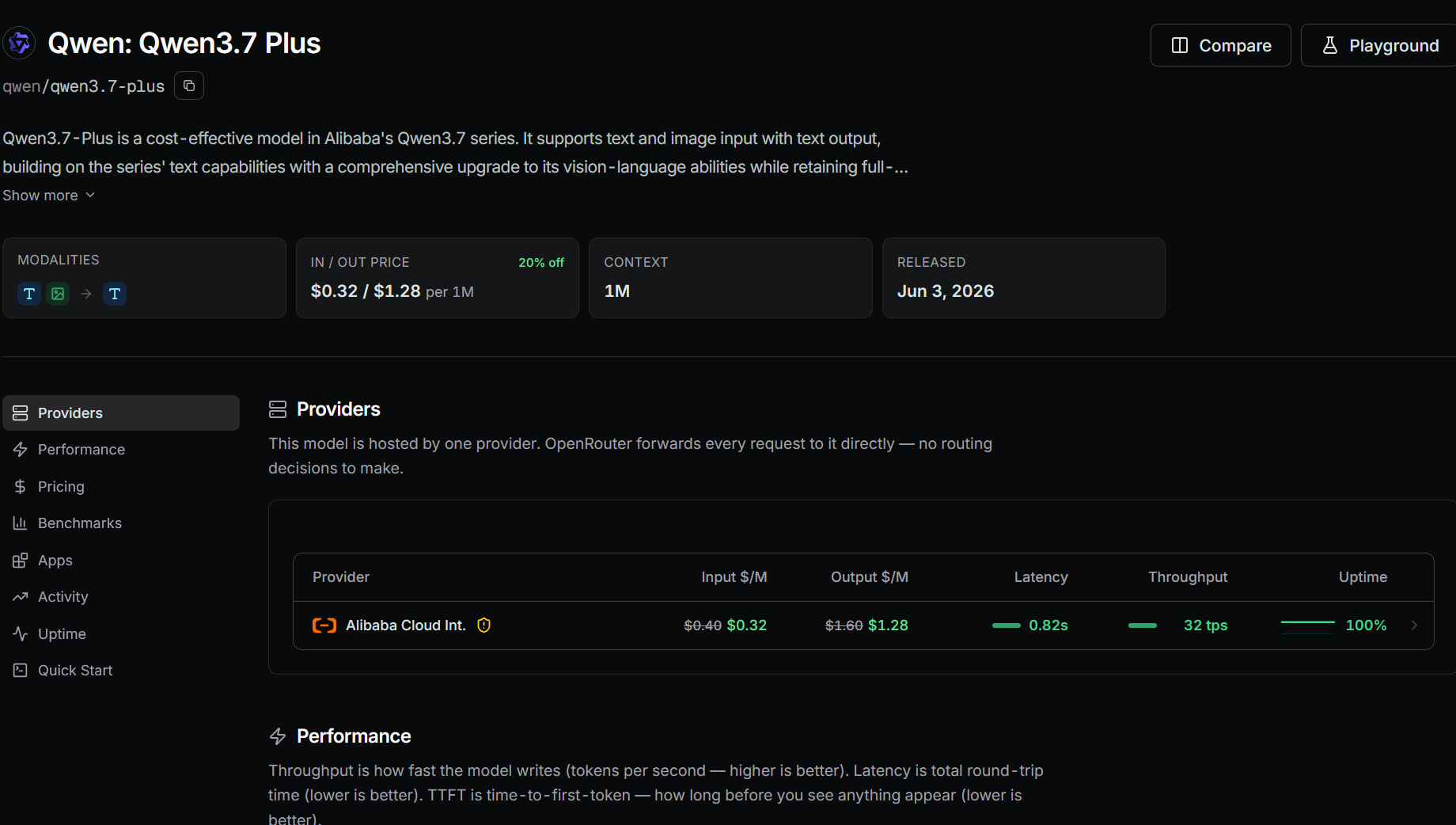
I use it when I want a general model from a different family than DeepSeek, especially for tasks that include screenshots, diagrams, or other visual input. Qwen3.7 Max sits one tier above it in my workflow.
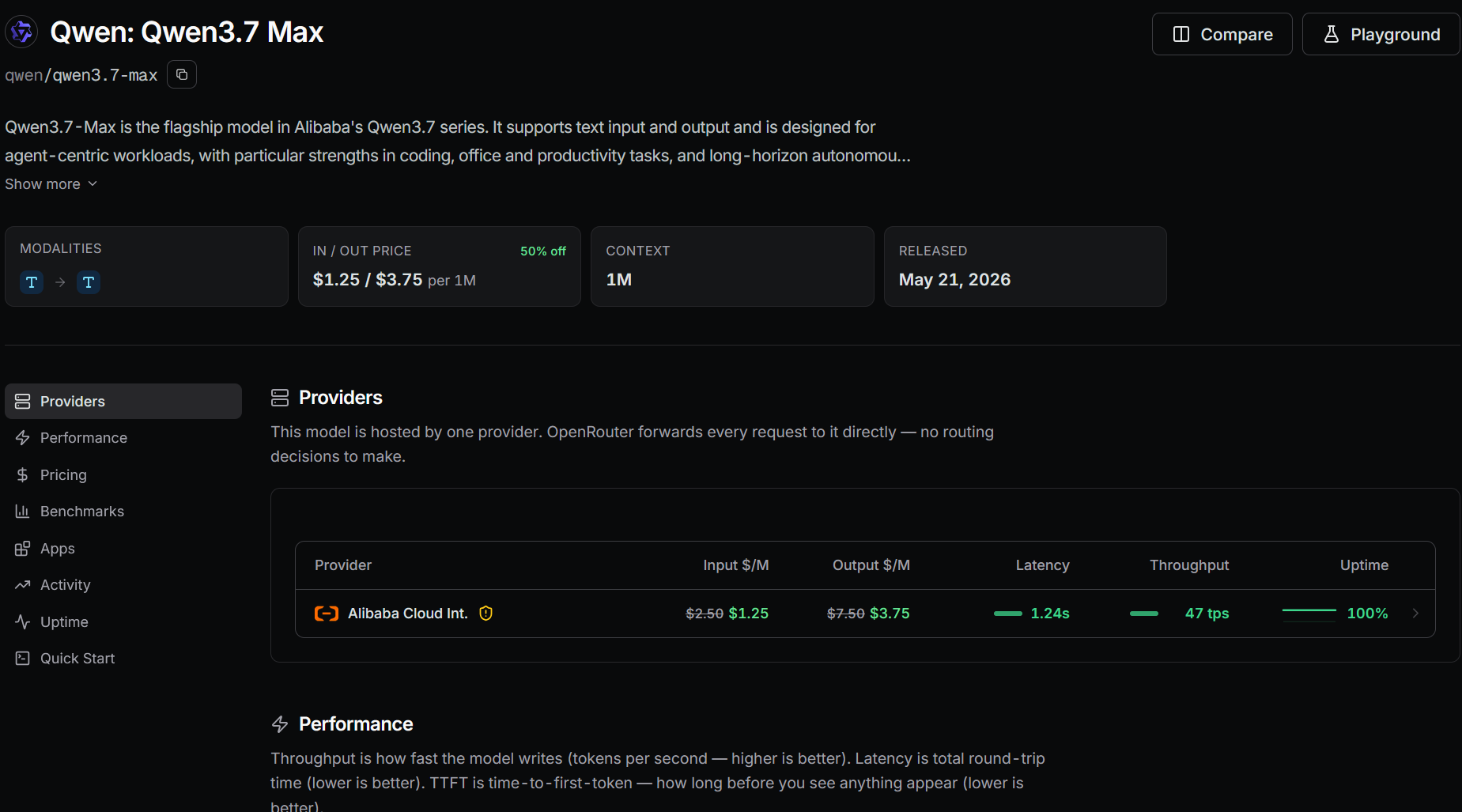
I reserve Max for work where the cheaper model has already failed, lost track of the task, or required several correction turns. The difference is not only the model name. Max is positioned as the flagship model, while Plus is the lower-cost option with text and image input.
DeepSeek V4 Flash and V4 Pro#
DeepSeek V4 Flash is usually my first hosted model for text and coding work.
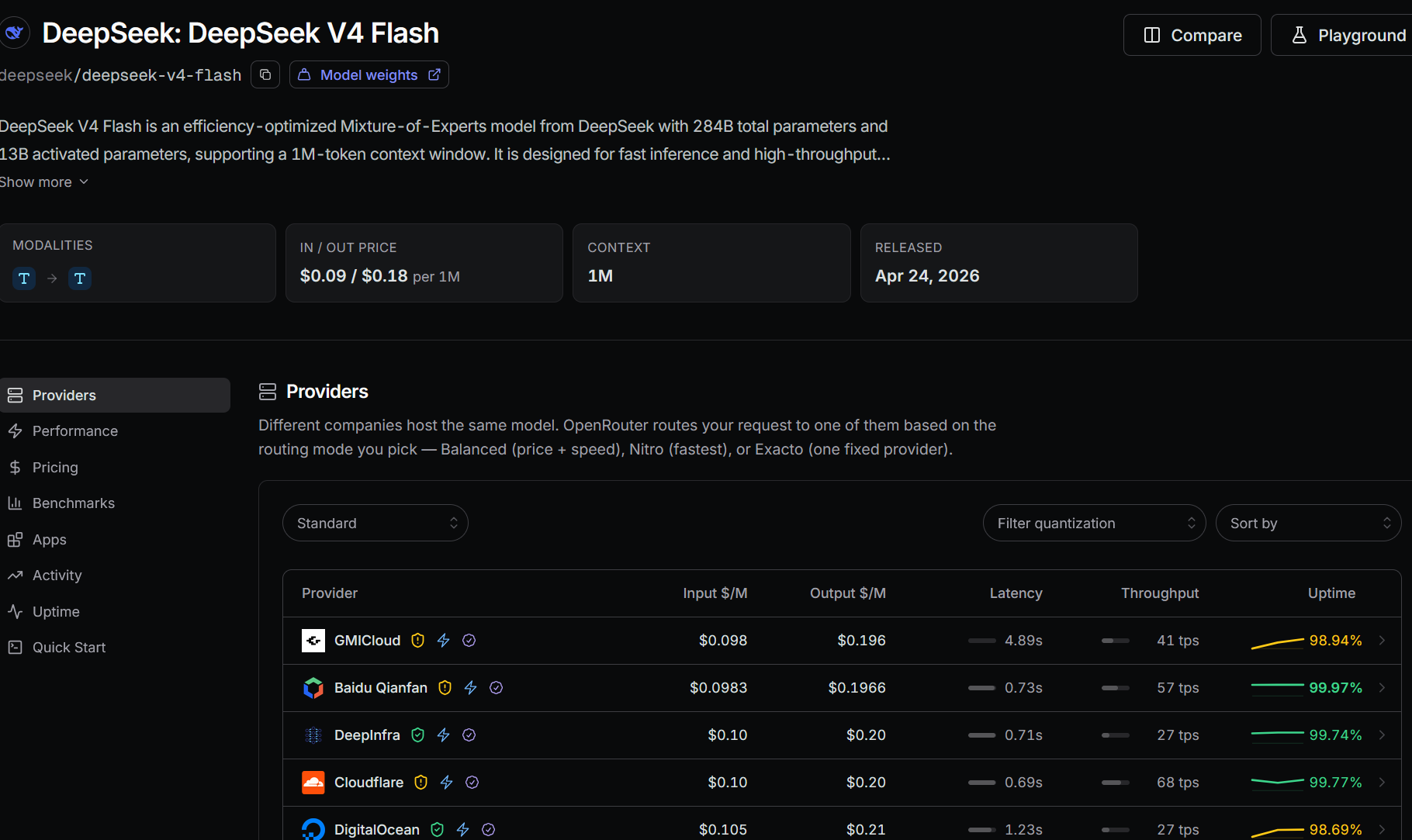
Its low token price makes it suitable for repository reading, code generation, brainstorming, and agent loops that would be expensive on a frontier API.DeepSeek V4 Pro is the next step when Flash starts losing track of a large change or repeating the same failed approach.
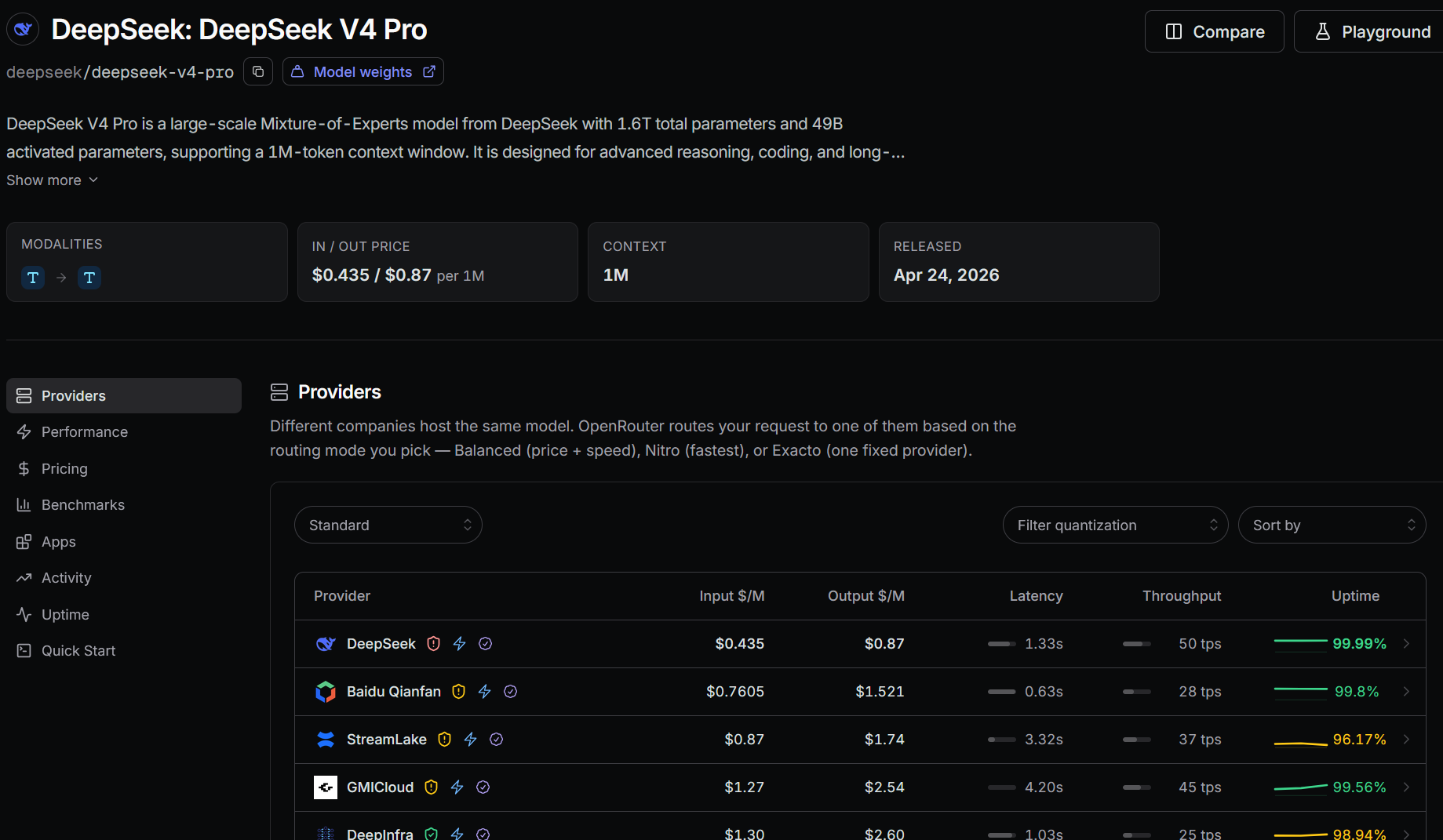
I move from Flash to Pro when I see a specific failure:
- The model forgets the original plan during a refactor.
- It edits one file while ignoring related files.
- It repeats an approach that has already failed a test.
- It needs several prompts to correct the same mistake.
Before changing models, I usually reduce the scope. I split the task into smaller changes, provide a file list, ask for a plan first, and limit the amount of repository context. Those steps often let Flash complete the work.
Kimi K2.7 Code#
Kimi K2.7 Code is the coding-specific model in this group.
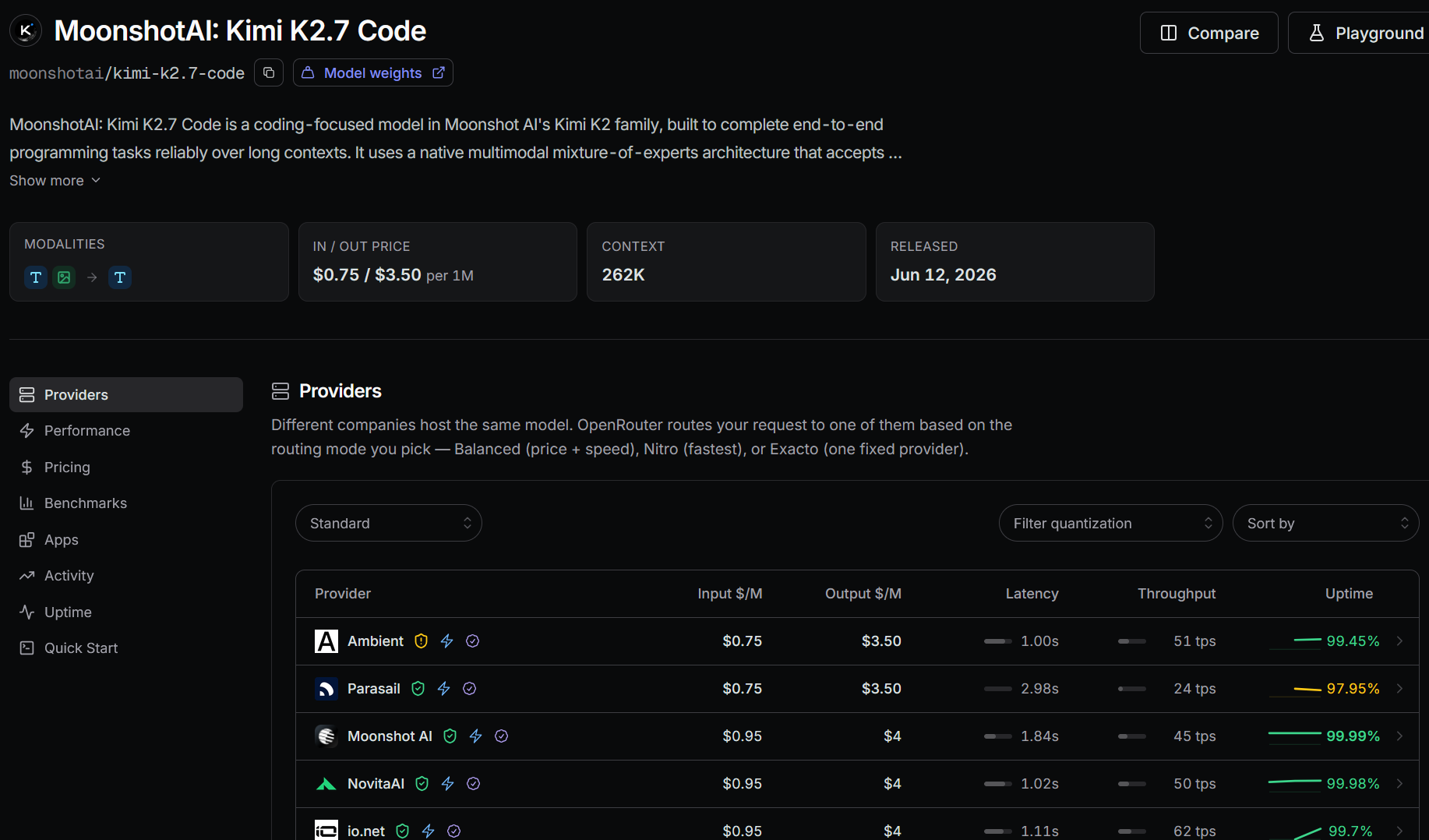
I use it as a second opinion for programming tasks, not as the first model for every request. Its context window is smaller than the 1 million token models in the table, and it is aimed at end-to-end software work.I still plan the task before handing it over. Coding models work better when they receive a defined sequence, a limited file set, and a test command. An open request such as “fix this repository” leaves too many decisions unresolved.
DeepSeek V4 Flash on Cloudflare and DigitalOcean#
The OpenRouter page for DeepSeek V4 Flash lists both Cloudflare and DigitalOcean as providers. That matters because the provider affects more than billing. It determines where the request is processed, which quantization is used, how prompt caching behaves, and what latency and throughput I see. Provider load, available capacity, routing, and the measurement window can all change. The provider choice is also useful when I want a repeatable test. If OpenRouter routes each request to a different backend, a change in the output could come from the prompt, provider, quantization, or model configuration. Pinning the provider removes one of those variables. Cloudflare and DigitalOcean also give me more control over which infrastructure company processes the request. That does not provide the same privacy as local inference. It does let me choose a provider whose terms and infrastructure I have already reviewed.
OpenRouter and direct provider APIs#
OpenRouter solves the model-switching problem. I can use one API and move between DeepSeek, Qwen, Kimi, and other model families without rewriting the agent integration. A direct provider API can still be the better choice for a stable workload. Prompt caching is the clearest example. Coding agents repeatedly send the same system prompt, repository map, instructions, and recently viewed files. When most of that input remains unchanged, the cache-read rate can decide the final bill. Some users have reported higher cache hit rates when calling DeepSeek directly than when sending the same workload through OpenRouter. I have not run a controlled test that confirms their reported ratios, so I treat the claim as something to measure. A useful comparison would keep the model, prompt, repository state, and number of turns fixed. I would record cached input, uncached input, output tokens, and total cost across several coding sessions.
Direct APIs also fit bursty side projects. A prepaid balance lets me spend nothing during a month when I do not code, then use the balance during a weekend project. A monthly subscription charges for the unused month. I keep both options available. I use OpenRouter when model choice matters. I use a direct API when one provider, one model, and one caching system produce a lower measured cost.
My current workflow#
At work, I use Claude Code because that is the tool available in my work environment. At home, I start with a local agent and move to a hosted model only after the local run shows a concrete limit.
local model
-> DeepSeek V4 Flash or Qwen3.7 Plus
-> DeepSeek V4 Pro or Qwen3.7 Max
-> Kimi K2.7 Code for a coding-specific second opinion
-> OpenAI or Anthropic only when the cheaper models fail
The trigger is not a benchmark score. It is a failed edit, a broken test, lost repository context, repeated correction turns, or a plan that does not match the code. This keeps expensive calls tied to evidence. The local agent gets the first attempt. OpenRouter supplies more compute when the task needs it. Direct APIs remain available when caching and provider behavior determine the result. The model is only one part of the system. A smaller model with a clear plan, a limited file set, and a working test loop often completes more useful work than a larger model given an entire repository and a vague request. That is the setup I want: local by default, hosted when necessary, and expensive only after the cheaper path has produced a measurable failure.